はじめに
昨年、Kubernetes上でCloud Native Storageを実現するRookについて調査しました。Rookは複数のストレージソフトウェアを統合しますが、最もよく使われるものがCephです。Rookについて調査・検証をするうちに、そもそもCephの動きを理解していない中でRookの理解を進めることが難しいと感じていたので、Cephについて調査しました。Cephは10年以上前に登場したストレージシステムのため、様々な書籍や記事でその機能や裏側の動きが紹介されています。今回はそれらの記事や論文、公式ドキュメントを眺めたうえでまとめ、自身のCephへの理解を深める第一歩として公開しました。誤った理解や記載がある場合は、ご連絡いただければ幸いです。
Cephとは
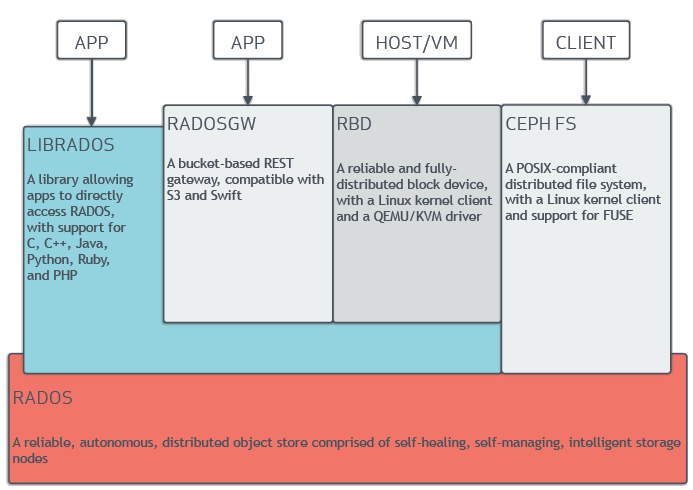
※Ceph公式ドキュメントより抜粋
Cephの登場する背景(論文より抜粋)
※論文では分散ファイルシステムであることを強調しているため、それに関連した導入となっている
- 大規模アプリケーションのパフォーマンスを向上するうえで、ファイルシステムのパフォーマンスは重要である
- パフォーマンスと拡張性を向上するため、分散ストレージシステムが有効であると考えられた
- 現在幅広く使われるNFSのようなサーバー/クライアントモデルによる「中央集権化」は、拡張性に問題を抱えている
- OSD(Object Storage Device)の登場により、クライアントはより多くのデータの読み書きが可能になった
- OSDの利用にもかかわらず依然残った問題として「メタデータの分散」がある
- 上記問題を解消するため、Cephが考案された
Cephコンポーネント
■クラスター
□RADOS
- Reliable Autonomic Distributed Object Store
- Cephのストレージクラスターの名称
□CRUSH
- Controlled Replication Under Scalable Hashing
- RADOSで利用される機能、分散したオブジェクトデータをどのストレージに配置するかを決定する
- 単一障害点、パフォーマンスボトルネック、物理的制約からの拡張性上限などを避けることができる
- ハッシュ関数を利用した計算により、分散データの配置を決定
- ストレージデバイスの階層情報、レプリカの複製ルールを設定する必要がある
□CRUSHマップ
- CRUSHアルゴリズムで利用される、ストレージデバイスのマッピング情報
- OSDリスト、Bucketリスト、ルールリストを含む
- 物理的な階層構造を反映し、隣接するデバイス間でレプリカを作成しないよう設定できる
- 異なるfailure domain間でレプリカを作成するよう配置する
□RADOSの各コンポーネント

1. OSD

※Ceph公式ドキュメントより抜粋
- それぞれの動作状態を相互監視
- write-ahead journalingの採用
- 実際の書き込み前にログに書き込む
- メタデータ+実データをjournalディスクに書き込む
- journalが溜まってからオブジェクトファイルに反映
2. MON
- Monitoring daemon
- クラスターマップ、クラスターの状態の管理
- 複数のMonが存在する場合はPaxosアルゴリズムに基づき合意形成
3. MDS
- Metadata Server daemon
- ファイルシステムのメタデータ(ディレクトリ、ファイル権限、アクセスモードなど)の保存・操作を行う
- ファイルストレージでのみ利用
- MDSがメタデータを担当し、クライアントはデータをOSDと直接やり取りすることでパフォーマンスを向上
- 複数のMDSを作成することで可用性・拡張性を提供

※Ceph論文(PDF)より抜粋
4. Placement Group
- OSDのリスト
- 後述のPoolが作成されるたびに設定される
- 分散データのオブジェクトはまずPG単位で分散し、PGに含まれるOSDにレプリカを作成する
- すべてのOSDに対して均等にオブジェクトが分散配置されるとは限らない(理由は後述)

5. Pool
- 以下の要素を含む論理的なグルーピング
- レプリケーション数の設定
- Placement Group
- CRUSHルール
- 指定したPoolのSnapshotを取得できる
■クライアント
□CephFS

※Ceph公式ドキュメントより抜粋
□RBD

※Ceph公式ドキュメントより抜粋
□RADOS GW

※Ceph公式ドキュメントより抜粋
Cephが分散ストレージを実現する流れ
■データのストライピング
- ファイルを受け取ると複数のオブジェクトにストライピングし、RADOSに保存
- 複数オブジェクトからの並列読み込みが可能になる
- ストライピングの方法として最も近いのはRAID-0
- クライアント側がストライピングを行う
- 3つの変数(オブジェクトサイズ、ストライプ幅、ストライプ数)

■データの分散配置
- CRUSHアルゴリズムに基づき配置する
- ストライピングしたオブジェクトをPGに割り当てる

■データの複製
- レプリカは同一PG内のOSD間で作成される
- 複製方式はprimary-copy replication方式


※Ceph公式ドキュメントより抜粋
■データの呼び出し
その他
■RADOSのデータ指定方法
■CRUSHアルゴリズム追記


■CRUSHで利用するハッシュ関数
- 多入力ハッシュ関数のJenkins hash関数を利用
■PGを利用する理由
- 分散ストレージではクラスターにストレージデバイスが追加された際にデータの再配置が発生し、場合によっては大規模なデータ移動が発生する
- 再配置時に大量のOSDが存在すると、組み合わせを決定するのが大変
- 複数のOSD間で格納するオブジェクトが分散されればよいので、あらかじめ分散対象のOSDを絞っておく
参考ドキュメント
Ceph: A Scalable, High-Performance Distributed File System (PDF)
CRUSH: Controlled, Scalable, Decentralized Placement of Replicated Data (PDF)
RADOS: A Scalable, Reliable Storage Service for Petabyte-scale Storage Clusters (PDF)
SlideShare - 分散ストレージソフトウェアCeph・アーキテクチャー概要
SlideShare - 分散ストレージ技術Cephの最新情報
NAKAMURA Minoru's Home Page - Ceph の覚え書きのインデックス
Wikipedia - Jenkins hash function
超ウィザード級ハッカーのたのしみ - Ceph, 特にCRUSHアルゴリズムについて