はじめに
本記事では、Kubernetesで実現するマルチテナントについて、2020年9月時点での現状と、将来的に利用できるであろう機能の紹介をいたします。各機能についての詳細は、参考ドキュメント等を参照していただければと思います。
本記事の要点
マルチテナントは単一のクラスター上に複数のテナントを共存させることを指す。
Kubernetesにはマルチテナントを実現するための機能が備わっている。
- アクセスコントロール:RBAC
- セキュリティ:Namespace / Network Policy / Pod Security Policy
- リソースの隔離:ResourceQuota / LimitRange / Affinity / Taintなど
Kubernetesのマルチテナント機能は、SIGを中心として機能開発が進められている。
- Benchmarks
- Tenant Controller
- Hierarchical Namespace Controller
- Virtual Cluster
マルチテナントとは
まずマルチテナントの概要を説明します。
マルチテナントについて理解するには、まずテナントとは何かを知る必要があります。テナントとは、CLI・API・UIなどのインターフェイスを通じて、システムへのアクセス権を持つユーザー・グループの集まりを指します。Kubernetesにおいては、kubectlコマンドやIngress/LoadBalancerなどのServiceリソース、Kubernetes Dashboardなどを通じて、Kubernetesクラスターリソースへのアクセス権を持つユーザー・グループのことを指します。
マルチテナントは、1つの共有リソース上に複数のテナントを共存させるような形態を意味しています。Kubernetesでは、複数のテナントが1つのKubernetesクラスターを共有することをマルチテナントと呼びます。
マルチテナント導入のメリット
マルチテナントを導入することでどんなメリットを得たいかといえば、大きく2つのメリットがあります。
コスト削減
各テナント毎に単一のクラスターを利用しようとすると、クラスターの数に応じて利用するためのコストが発生します。クラウドでは利用した個数と時間だけの利用コストが発生し、オンプレでは機器購入や発注コストが発生します。
また、テナント毎にクラスターを用意すると、各クラスターでのリソース使用率にばらつきが生じ、効率的にリソースを利用することができなくなります。
マルチテナントを採用することで、クラスターの利用にかかる金額やリードタイムといったコストを削減することが可能になります。また1つ、あるいは少数のクラスターを利用することで、リソースの使用効率も上昇します。これらの効果は、テナントの数が増加するほど顕著になり、コストメリットは増加します。
運用負担の軽減
テナント毎にクラスターを用意すると、各テナントに対するオペレーション作業を行う際、各テナントに対する操作を実行するため、操作対象のクラスターを切り替える必要があります。
テナント数が増加するほどオペレーションの負担は増加し、特に少人数で運用を行うチームへの影響が大きくなります。
マルチテナントを採用することでクラスターの切り替えコストを軽減し、運用負荷を軽減することが期待できます。
小規模システムの場合
こちらはシステムの規模が小規模な場合のメリットとなります。開発中、あるいはリリース直後のサービスでは、システムを利用するユーザーも少ないと予想されます。1つのクラスターの持つ処理能力でシステムを運用するのに十分であれば、マルチテナントを導入することでコストを削減できます。
また開発・運用チームへのメリットとして、単一のクラスター上でシステムを運用することで、複数テナントに対しての機能追加を反映しやすい、システム上のボトルネックがどこになるかを早めに予測することがメリットとして考えられます。
※参考リンク:
マルチテナントの種類
マルチテナントには大きく2種類のモデルがあり、リソースを共有するテナントをどうとらえるかによってモデルが変化します。
Soft Multi-Tenancy
Soft Multi-Tenancyの場合、各テナントは「信頼できる」ユーザーの集まりととらえます。例としては、社内の複数開発チームがクラスターを共有する場合が考えられます。Soft Multi-Tenancyでは、操作ミスなどの影響が他のテナントに広がらないよう、テナント間を分離することが主な目的となります。
Hard Multi-Tenancy
Hard Multi-Tenancyの場合、各テナントは「信頼できない」ユーザーの集まりととらえます。例としては、複数の企業やユーザーが利用するサービスをマルチテナントで提供する場合が考えられます。各テナントには悪意ある行動をとるユーザーが含まれると考え、悪意ある行動が他のテナントに影響しないように分離をする必要があります。
Hard Multi-Tenancyを紹介する資料の1つに「Coke & Pepsi on the same k8s cluster」というワードを確認することができますが、これはHard Multi-Tenancyを端的に表すキーワードだなと個人的には感じました。
マルチテナント導入に向けて考えること
マルチテナントを実現するためには、あるテナントでの操作が他のテナントに影響を与えることが無いよう、3つの観点から考える必要があります。
アクセスコントロール
あるテナントのユーザーが、故意か否かに関わらず、他のテナントへのログインができないようにしなければなりません。
各テナントには、利用を許可された特定のユーザーしかログインすることはできないようにする必要があります。また各ユーザーには適切な権限が付与されており、必要以上の操作は実行できないようにします。
セキュリティ
アクセスコントロールとも関連しますが、あるユーザーが他のテナントのリソースにアクセスできないようにする必要があります。
異なるテナント間では互いに利用するリソースは見ることができず、Requestの傍受などによる干渉をすることもできないようにします。またクラスターNodeのカーネルにアクセスし、権限の昇格を行うことも防がなければなりません。
リソースの隔離
特定のテナントが大量のリソースを利用し、他のテナントが利用できるリソース量が少なくなるようなことがあってはなりません。各テナントが利用できるリソースは公平になるよう制御を行う必要があります。またあるテナントがKubernetesに独自のAPI・CRDを追加したときに、他のテナントとの間で競合しないようにする必要もあります。
Kubernetesでのマルチテナント
ここからはKubernetesのマルチテナントに焦点を当てます。
Kubernetesでのマルチテナント提供方法
Kubernetesのマルチテナントの実装の前に、マルチテナントをどのような形で提供するかについて確認したいと思います。Kubernetesでは、マルチテナントを実現するために、複数の機能を組み合わせる必要がありますが、テナントの提供方法を念頭に置きながら眺めることで、どの機能を組み合わせて利用するかを考えやすくなると、個人的には考えています。
Kubernetesでのマルチテナント提供方法には、大きく2つの方法があります。提供方法の違いによって、各テナントがKubernetesにアクセスする際のインターフェイスが変化し、マルチテナントを実現するうえで必要になるKubernetesの機能も変化してきます。
Kubernetes環境そのものを提供する場合:Kubernetes環境そのものを複数のテナントに提供する場合は、主にkubectlコマンドなどを経由してアクセスすることになり、Kuberentes APIを共有する形になります。例としては、社内の複数開発チームが一つのクラスターを共有する場合などが挙げられます。
Kubernetes上で動作するアプリケーションを提供する場合:Kubernetes上のアプリケーションを提供する場合、各テナントは主にIngress/LBといったServiceリソースを経由して、Podで稼働するアプリケーションへアクセスすることになります。例としては、複数の企業やユーザーに対して提供するサービスなどを運用する場合が挙げられます。

マルチテナントの実現
Kubernetesは、もともとマルチテナントを考慮した設計がされていませんでした。OpenStackではUser / Tenant / Projectといったリソースを利用することができますが、Kubernetesにはテナント用のリソースというものは用意されていません。
一方でKubernetesには多くの標準機能が備わっており、その中にはマルチテナントを実現することを助けるようなものも含まれます。ここでは、Kubernetesの機能の中から、マルチテナント実現に利用されるものを紹介します。
アクセスコントロール
RBAC
RBAC(Role-Based Access Control)は、ユーザーに対してロールを付与することで、アクセスできるリソースの種別と操作内容を制御する機能です。Kubernetesにはユーザーとロールにそれぞれ2種類のものが用意されています。
- ユーザー
- UserAccount:Kubernetes外部の独立したサービスが提供するアカウント。クラウドプロバイダーが提供するIAMなどがこれにあたり、KubernetesにはUserAccountに該当するリソースは存在しない。
- ServiceAccount:Kubernetes内部でのみ利用できるアカウント。各リソースを操作するにはServiceAccountを指定する必要があり、指定がない場合はdefaultのアカウントが利用される。
- ロール
- Role:後述するNamespaceに対しての権限を付与するために利用する。
- ClusterRole:特定のNamespaceだけでなく、Namespaceをまたがるようなもの、クラスタースコープなリソースに対しても権限を付与することができる。
以下の図では、あるユーザーにPodへのアクセスコントロールを設定し、Podの情報取得(kubectl getコマンド)は実行できるが、Podの作成(kubectl createコマンド)は実行できないような場合を例として載せています。

※参考リンク:
セキュリティ
Namespace
NamespaceはKubernetesの環境を分離するうえで重要となる単位です。Kubernetesで利用できる機能はNamespace単位で適用するものが多く、セキュリティや認証の境界として利用されます。
KubernetesではNamespaceを利用することで仮想的なクラスターの分離を実現します。Namespaceは主に2つの機能があります。
- リソース名の境界:Namespace内では一意なリソース名しか利用することができません。一方でNamespaceが異なれば同一のリソース名を利用することができます。
- 認証・ポリシーの境界:Kubernetesの提供する認証。ポリシー管理機能の多くはNamespaceを単位として利用します。前述のRBACや後述する各ポリシーの多くは、Namespaceを指定して作成することで有効にできます。
※参考リンク:
Network Policy
Network Policyは、クラスター内のPod間の通信を制限する、FWのような機能を提供します。Network PolicyではPodに付与するLabelや送信元・宛先アドレスやポートを利用し、特定のPod間の通信制御を行うことが可能です。
Network PolicyはNamespaceごとに作成する必要があり、またCNIによってはNetwork Policyを利用できない場合があります。Network Policyを利用する場合は、事前に適用可能なCNI(例:Calico、Cilium、Weave Netなど)を用意する必要があります。
以下の図では、特定のNamespaceに対してNetwork Policyを適用し、app: webLabelの付与されたPodからのInbound通信のみを許可した場合を載せています。

※参考リンク:
Pod Security Policy
Pod Security Policyは、Podに対するセキュリティポリシーを設定するために利用します。設定できる内容には、以下のようなものがあります。
| パラメータ名 | 機能 |
|---|---|
privileged |
特権コンテナを利用するか否か |
hostNetwork |
ホストネットワークを利用するか否か |
readOnlyRootFilesystem |
ルートファイルシステムをread onlyにする |
selinux |
コンテナ内のSELinuxの設定 |
Pod Security Policyはクラスター全体に対して適用するポリシーです。RBACと組み合わせることで、ユーザーごとに適用するポリシーを変更することができます。
※画像:sysdig blogより

※参考リンク:
リソースの隔離
ResourceQuota / LimitRange
ResourceQuota/LimitRangeは、Pod/Container/PVCなどのリソースが利用できるリソース使用量の制限を行います。ResourceQuotaはNamespaceに適用し、各Namespace内のリソースの合計値を制限するのに利用します。LimitRangeは各リソース個別のリソース使用量を制限します。
制限可能なリソースとしては、各PodのCPU/メモリ利用量の上限・下限、Deployment/Service等リソース種別ごとの個数の上限などがあります。

※参考リンク:
Affinity/Anti-Affinity
Affinity/Anti-Affinityは、Podのスケジューリングに関する条件を付与する機能です。AffinityはNode/Podに付与したLabel情報を元に、Podを特定のNode、あるいは特定のPodが存在するNodeにスケジュールする仕組みです。
Affinityが未指定の場合、利用できるすべてのNodeがスケジュール候補となります。また、Podがスケジュールされた後にスケジュールポリシーが変更された場合も、スケジュールされたPodはそのまま同じNodeに残り続けます。
以下の図は、disktype: hddのLabelが付与されたNodeの中から、kubernetes.io/hostname: node2のものを優先してスケジュールするように設定した例になります。

※参考リンク:
2020/9/6追記:Affinity/Anti-Affinityは、マルチテナントを実現するうえでは必ずしも利用する機能ではありませんが、「Kubernetesが備えているリソースの隔離機能」という括りで紹介いたしました。
「AffinityやTaintはPod を作る側に決定権があるため、マルチテナントのための機能とは毛色が違う」というコメントをいただいたため、こちらに追記いたしました。
Taint/Toleration
前述のAffinity/Anti-Affinityが特定のNodeにPodをスケジュールするための仕組みだったのに対し、Taint/Tolerationは特定のNodeにPodがスケジュールされるのを避ける仕組みになります。NodeにはあらかじめTaint(汚れ)を付与しておき、Taintに対するToleration(耐性)を持つPodだけがそのNodeにスケジュールされ、条件に一致しないPodはスケジュールされません。
利用例としては、本番環境専用のNodeやGPU等を備えた特殊なNodeを利用する場合が挙げられます。
PodにTolerationを指定しない場合、Taintの設定されたNodeはスケジュール対象外となります。また、Taint/Tolerationの場合、後からスケジュールポリシーが変更されると、条件に一致しないPodは別のNodeへ退避されます。
以下の図では、env=prd:NoScheduleというTaintを付与したNodeにスケジュールされるよう設定したPodの例を載せています。

※参考リンク:
2020/9/6追記:Taint/TolerationもAffinity/Anti-Affinityと同様、マルチテナントを実現するうえでは必ずしも利用する機能ではありませんが、「Kubernetesが備えているリソースの隔離機能」という括りで紹介いたしました。
各クラウドベンダーでの対応
マネージドなKubernetesサービスを提供するクラウドプロバイダーは、Kubernetesの標準機能に加え、各プロバイダーの提供するサービスを利用したマルチテナント構成の例を紹介しています。ここでは、代表的なクラウドプロバイダー3社のドキュメントから、特徴的な機能を簡単に紹介します。
Amazon Web Services (EKS)
- IAMとRBACの連携:AWS EKSはAWS IAMとRBACを統合して、IAMユーザーとロールに対してRBACを適用することが可能です。
- EKS on Fargateの利用:Fargateを利用することで、利用者はData Planeを管理する必要がなくなります。また各Podはそれぞれ別のVM上で動作するため、Pod間でリソースを共有せず、Pod間隔離が強化されます。
- AWS App Mesh:マネージド型のサービスメッシュであるApp Meshを利用することで、ネットワークトラフィックの制御を行うことができます。
※参考リンク:
Google Cloud (GKE)
- IAMとRBACの連携
- Project/Folder:Google Cloudの管理単位であるプロジェクト、複数のプロジェクトを束ねるフォルダを利用することで、管理上の問題を分割することができます。
- 共有VPCの利用:共有VPCを利用することで、プロジェクトの境界を超えたネットワークリソースの管理が可能になります。
- GKE Sandbox:GKE Sandboxを利用することで、GKE上でgVisorを利用し、コンテナランタイムセキュリティを強化することができます。
- Workload Identity:KubernetesがGoogle Cloudサービスへアクセスするのに使用するServiceAccountを、Google Cloud ServiceAccountと紐づけ、セキュリティや管理性を向上します。
※参考リンク:
Microsoft Azure (AKS)
- Azure ADとRBACの連携
- Azure Policy:AKS専用のポリシーを利用し、セキュリティを強化します。
- Azure AD Pod Identity:Azure ADと連携して、PodがAzureサービスにアクセスすることを可能にします。
※参考リンク:
Kubernetesディストリビューションでの対応
Kubernetesディストリビューションには、マルチテナントに対応するための機能を備えたものが存在します。
例えばRancherではProjectという機能があり、複数のNamespaceを束ね、一括でポリシーを適用することが可能です。これにより、マルチテナントで発生するであろう大量のNamespaceの管理とポリシーの適用にかかる負担を軽減することができます。
※画像:Rancherドキュメントより

将来Kubernetesが実現するマルチテナント実現方法
ここまでで、Kubernetesのマルチテナントに関する現状を眺めてきました。ここからは、将来的に利用できるであろうKubernetesのマルチテナント実現機能について見ていきます。
Kubernetesコミュニティについて
Kubernetesのマルチテナントについて触れる前に、Kubernetesとコミュニティのかかわりについて少しだけ触れておきます。
Kubernetesの開発や運用は巨大なコミュニティによって支えられており、その中にはSIG(Special Interest Group)というグループが存在します。SIGはKubernetesの特定のトピックに焦点を当てて議論や実装を行うグループであり、2020年9月時点で100以上のグループが存在します。
SIGにはmulti-tenancyというグループも含まれており、ここではKubernetes上でのマルチテナントに関しての議論や開発が行われています。
※参考リンク:
マルチテナントアーキテクチャのパターン
ここからは、multi-tenancy SIGの活動の中から幾つかのトピックについて紹介します。
上述のmulti-tenancy SIGでは、マルチテナントを実現するアーキテクチャを4つ提言しています。4つのアーキテクチャの概要は、以下の画像の通りです。2019年時点(現在も?)では4つのアーキテクチャのうち、パターンB、Tenant+Namespaceのアーキテクチャを実現することに焦点を当てていたようで、それに関わるプロダクトの開発も行われています。
※画像:KubeCon US 2019スライドより
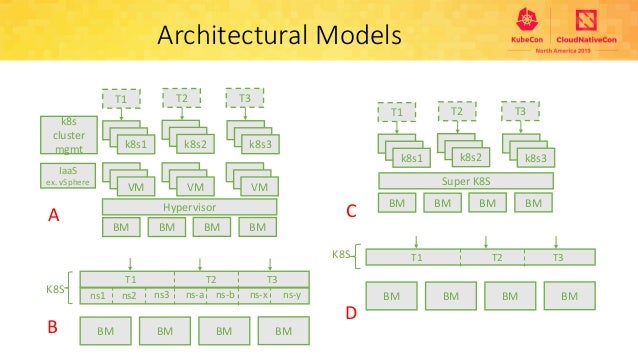
- Hypervisor上に複数のKubernetesクラスターを作成:HyperVisor上に複数のKubernetesクラスターを構築し、テナントごとにクラスターを提供する。リソースの利用効率は低いが、テナント間の隔離レベルは高い。
- TenantによるNamespaceのグルーピング:テナントごとにTenantというリソースを用意し、複数のNamespaceを管理する。リソースの利用効率やテナント間の隔離レベルは比較的高いが、クラスタースコープなリソースに対する制約がある。
- Virtual Kubernetes Cluster:Kubernetesクラスター上に複数の仮想Kubernetesクラスターを作成し、テナントごとに仮想クラスターを提供する。テナント間の隔離レベルも高く、大きな制約は存在しない(と思われる)が、現時点ではアーキテクチャとしての成熟度が低い。
- Kubernetesのコア機能の変更:Kubernetesのコアの設計を変更し、Tenantをファーストクラスのリソースとして追加する。まだ構想段階で、デザインも存在しないと思われる。
開発プロダクトの紹介
multi-tenancy SIGでは、現在4つの機能・プロダクトを開発しています。
Benchmarks
Benchmarksは、あるクラスターがマルチテナント向けに設定されているかをテストするベンチマークを提供します。ベンチマークには、クラスターの設定ファイルをチェックするタイプと、テスト用Namespace内での振る舞いを見る振る舞いチェックの2種類が存在し、複数のカテゴリに分かれたチェック項目をテストします。現時点では開発中のフェーズですが、E2Eのバリデーションテストも提供されています。
※参考リンク:
Tenant Controller
Tenant Controllerは、クラスター内でTenantリソースを実現し、複数のNamespaceを束ねる機能を提供するコントローラーです。前述のRancher Projectのような機能だと考えてもらえると、分かりやすいかもしれません。
Tenant Controllerは主に2つのCustom Resourceをコントロールします。
Tenant:複数のNamespaceを含むCustom Resource。Tenant AdminというServiceAccountをリソース内で指定することで、RBACを自動的に更新し、Tenantへのアクセスを管理します。TenantNamespace:Tenantで利用するNamespaceを明示するCustom Resource。
またPoCではNamespaceTemplateというCustom Resourceも存在し、Namespaceとそこで利用するポリシーなどを定義することができます。TenantNamespaceでNamespaceTemplateを指定することで、Namespaceに対するポリシーを適用したTenantを用意することができます。
※参考リンク:
Hierarchical Namespace Controller
Hierarchical Namespace Controller(HNC)は、名称の通りNamespaceを階層構造に管理する機能を提供します。Namespaceを階層構造にすることで、従来複数のNamespaceを管理するうえで問題となった以下のような点を解消することを目指しています。
複数のNamespaceに対するポリシーの適用
複数のNamespaceに対して共通のポリシーを適用する場合、これまでは全てのNamespaceに対するポリシー適用作業が必要となっていました。これはNamespaceが多くなるほど影響が大きくなり、開発チームや組織、サービスが拡大するにつれて顕著になります。
HNCは親Namespaceに適用したポリシーを子Namespaceに伝播することが可能であり、複数Namespaceに対する共通ポリシーの適用が容易になります。また親Namespaceから伝播したポリシーは、子Namespace側から削除することはできず、ポリシーの強制力を持たせることもできます。
なお、親Namespaceから子Namespaceへ伝播するリソース種別はHNCConfigurationで指定することが可能です。
Namespace作成時の権限
Namespaceを作成するにはクラスターレベルの権限が必要であり、権限を制約されたメンバーがNamespaceを作成するには都度管理者への作業申請が必要でした。
HNCでは、子Namespace(Subnamespace Custom Resource)の作成にはクラスターレベルの権限が不要のため、申請等の作業を挟まずリソースの作成が可能になります。
※画像:KubeCon US 2019スライドより
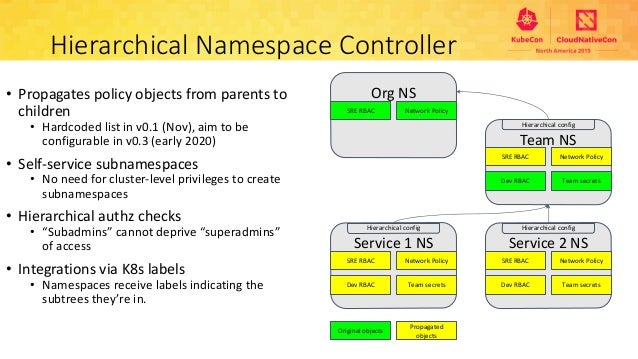
※参考リンク:
GitHub - kubernetes-sigs/multi-tenancy: The Hierarchical Namespace Controller (HNC)
amsy810's Blog - Hierarchical Namespace で Namespace を階層構造に管理してオブジェクトを伝搬させる
Virtual Cluster
従来のKubernetesマルチテナントにおける課題の一つに、Control Planeの分離能の問題があります。
各テナントで同一のKubernetes APIを共有する場合、例えば1つのテナントから大量のリクエストがAPIに向けて飛んでくると、他のテナントからのリクエストに応答できない可能性があります。これは特定のテナントからのDoS攻撃を受け、それが他のテナントにも影響した状態であるため、マルチテナントの目指す状態(個々のテナント間での操作はほかのテナントに影響しない)とは異なる様子であると言えます。
このようなControl Planeに関する問題を解消するため、各テナント毎に仮想のControl Planeを用意し、Control Planeの分離能を高めることを目指したのがVirtual Clusterです。
Virtual Clusterは前述のTenant Controllerを利用してテナント毎にTenant Custom Resourceを用意し、各テナント毎にkube-apiserver / etcd / controller managerなどを作成します。各テナント内での操作は、仮想クラスターによって実現され、各テナントの情報はSuper Master Kubernetesと同期されます。またテナント間の通信はSyncerというコンポーネントによって制限されるため、クラスタースコープのリソースを、他のテナントに影響することなく作成することができます。
※画像:KubeCon Europe 2020スライドより一部抜粋

※参考リンク:
















 ※上図は元記事より引用
※上図は元記事より引用 ※上図は元記事より引用
※上図は元記事より引用









{kind=link}