CephのBest Practiceを探る④:RHCSの更なるパフォーマンス調査
はじめに
本記事はCephのBest Practiceを探る第4弾になります。今回も先日紹介した記事の続編として、Cephの公式ブログで公開されているこちらの記事の内容を紹介いたします。今回も記事内容への補足や個人的なメモは青文字で加えております。なお、本記事を含めてこれまで4回ほど続けてきたこのシリーズは、本記事執筆時点ではこれで最後となります。
要点
- Part 4では、Part 1からPart 3まで検証したことに加え、様々な観点から行ったパフォーマンス検証の結果をまとめています。
- 1デバイスあたりのOSD数を変更した結果、2OSDが理想的な比率であり、4OSDの場合はCPU使用率が増加したにもかかわらずIOPSがそこまで改善されませんでした。
- デバイスあたりのCPU Coreを追加した結果、Random Write、Random Read-WriteのIOPSが改善されました。またBlueStoreではCPU CoreとNVMeとの比率は6:1が適切な比率であるとわかりました。
- RHCSのPool Replica数を少なくした結果、IOPSとレイテンシの改善が見られました。一方Random Readのパフォーマンスは改善が見られませんでした。
- BlueStoreキャッシュ数を8GBまで増強した結果、IOPSとレイテンシの改善が見られました。
- Intel Optane P4800xをWAL/RocksDBデバイスとして利用した結果、IOPSとレイテンシの改善が見られました。
検証環境
今回の検証環境は、これまで利用してきたRHCSの環境を引き続き利用します(詳細はPart-1を参照)。
1. 4 OSDs vs. 2 OSDs per NVMe Device
Ceph FileStore OSDを利用する際、デバイスあたりのOSD数は4と設定されることが一般的でした。BlueStoreが開発されたことでOSDあたりのパフォーマンスが向上し、1つのデバイスに2つ以上のOSDを設定することでの効果が少なくなってきました(※1参照)。このベンチマークでは、(BlueStore利用時)デバイスあたりのOSD数は「2」が最適である、という仮説を立て、それを検証しました。
※1:OSDあたりのパフォーマンスが向上し、利用するデバイスの出力できるパフォーマンスの「上限」に達するまでのOSD数が減少した、ということ?
検証の結果は以下のグラフの通りとなります。2つのグラフは横軸にブロックサイズを、縦軸にはIOPSとCPU使用率・レイテンシの結果をそれぞれプロットしています。
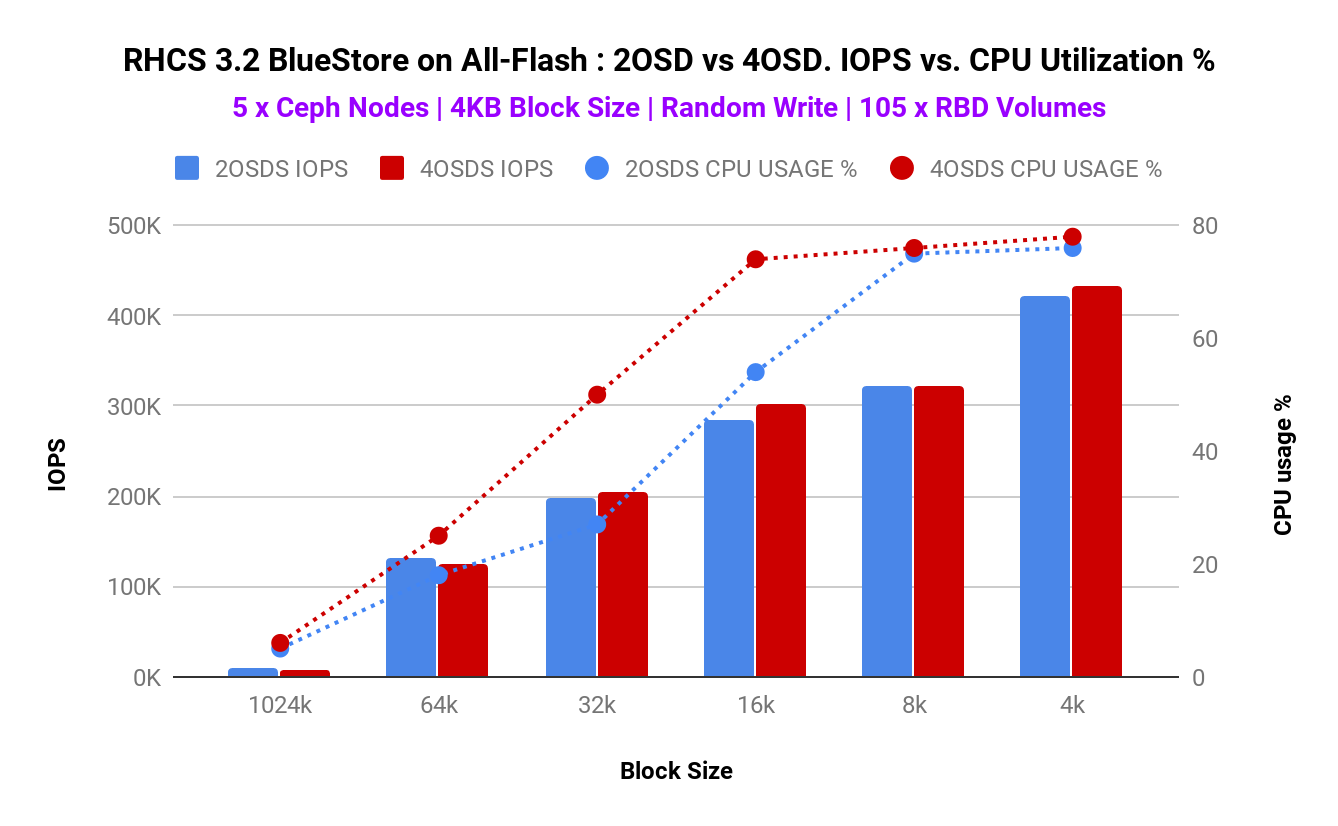
Graph 1:2OSD vs 4OSD(CPU使用率)
Graph 2:2OSD vs 4OSD(レイテンシ)
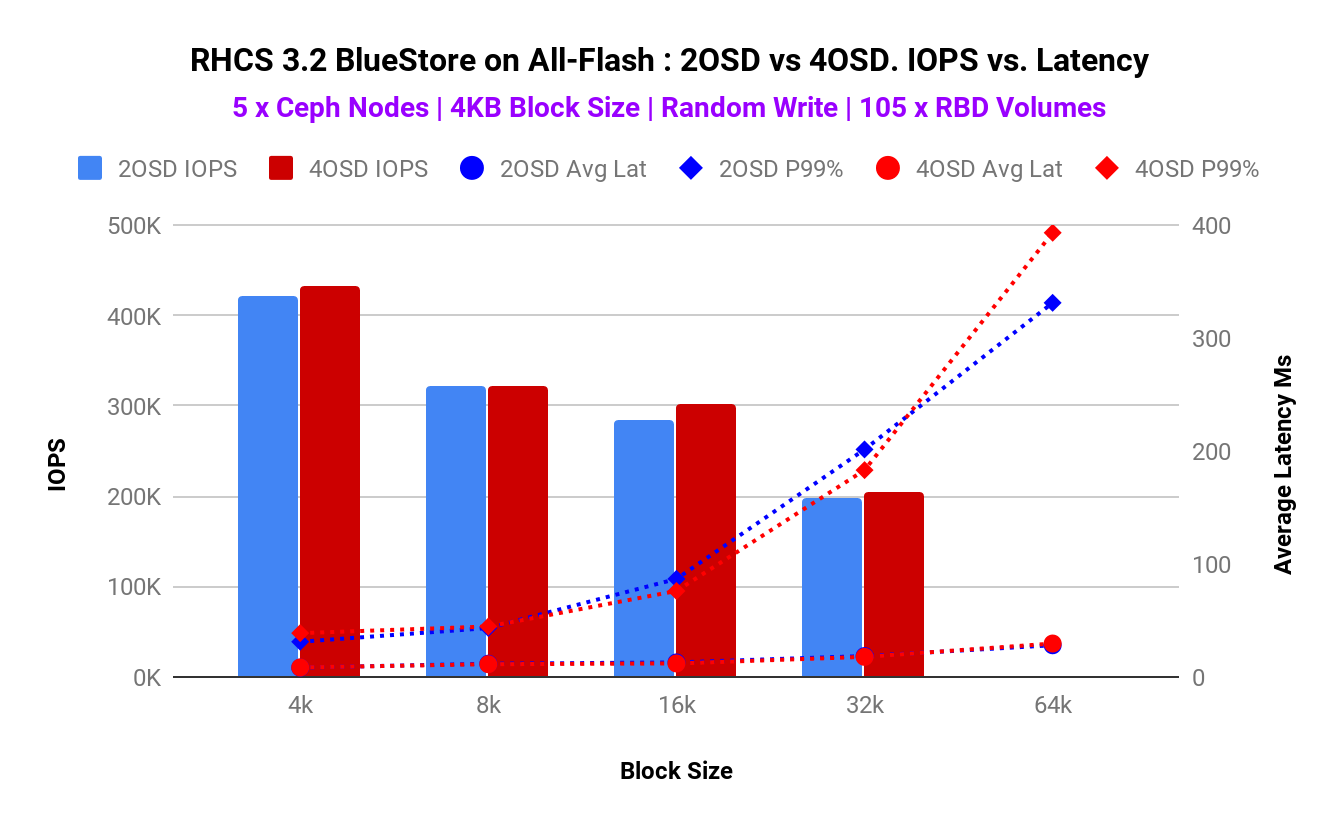
上記グラフから、次のことが言えます。
- Graph 1より、OSD数を変更してもIOPSにはほとんど変化が見られないことがわかります。また、IOPSはほとんど変わらないにもかかわらず、CPU使用率は2OSDのほうが少ないことがわかります(※2参照)。
- Graph 2より、2OSDのほうがレイテンシも少ないことが分かります(※3参照)。
- これらの結果は、本検証時に建てた仮説(BlueStore利用時は、デバイスあたりのOSD数をより少なくしたほうが良い)と一致するものといえます。
※2:Graph 1を見ると、CPU使用率は2OSDのほうが常に少ないですが、ブロックサイズが小さいときはほとんど違いはなく、ブロックサイズが16k ~ 64k(Part 2の区分けで言う”Middleブロックサイズ”に相当)の時に大きな違いが見られます。そのため、OSDのCPU使用率については、利用するブロックサイズも大きく影響していると言えそうです。
※3:Graph 2を見ると、ブロックサイズが64kの時は、2OSDのTailレイテンシは4OSDのものと比べて大きく減少していることが見られますが、それ以外はほとんど違いが見られず、ブロックサイズが16k~32kの時には逆に2OSDのほうがTailレイテンシは増加しています。このため、Graph 1と同様、OSDあたりのレイテンシについても、ブロックサイズが大きく影響していると言えそうです。
2. CPU Core to NVMe Ratio
ここでは、NVMeデバイスあたりの物理的CPUコア数の適切な比率を求めることを目的としています。検証の結果は、以下のグラフの通りです。横軸にデバイスあたりのコア数、縦軸はワークロードごとのIOPSを表しています。なおIO Depthは32で固定です。
Graph 3:Physical Cores per NVMe
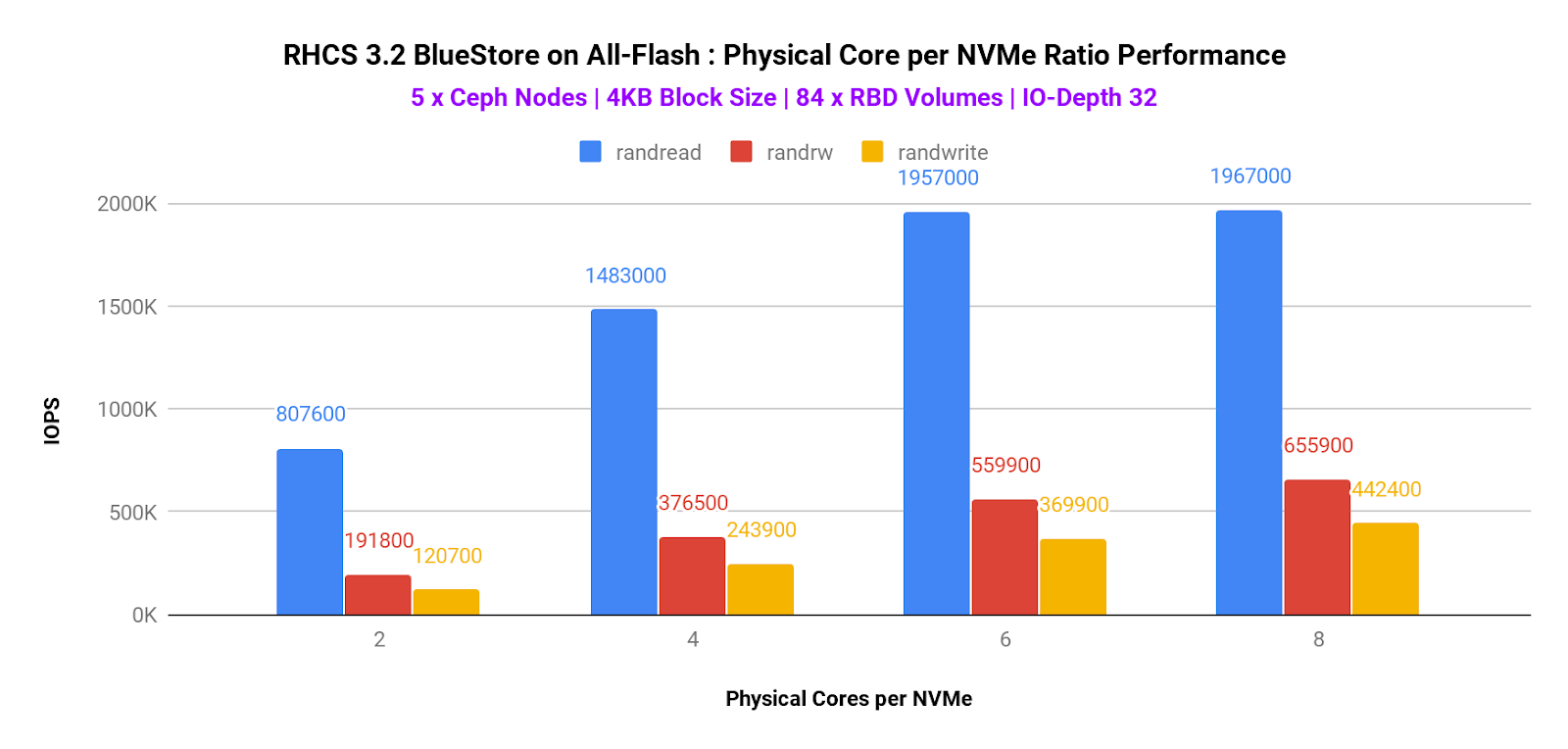
Table 1:デバイスあたりのコア数の変化によるIOPSの改善率
| Workload | IOPS増加率 (4->6) | IOPS増加率 (6->8) |
|---|---|---|
| Random Read | +31.96% | +0.51% |
| Random Read-Write | +48.71% | +17.15% |
| Random Write | +51.66% | +19.60% |
上記グラフより以下のことがわかります。
- Random Read-Write、Random Writeワークロードでは、デバイスあたりのCPUコア数を増加させるにしたがって、IOPSが向上しました。これは以前Smallブロックサイズで行った検証と一致する結果です(※4参照)。
- Random Readでは、CPU数を6から8に変更したときにほとんど変化しませんでした。以前の検証結果を思い出してみると、メディア使用率は88%まで上昇していたため、これが影響している可能性もあります(※5参照)。
- 以上の結果から、BlueStore利用時は、デバイスあたりのコア数を「6」に設定するのが最も適切であると分かりました。6以上の数値にしても効果が少なく、コスト的に見合わなくなる可能性があります。また、FileStore利用時は、デバイスあたりのコア数は「10」がよく使われていたことから、BlueStoreを利用することで、パフォーマンスの改善だけでなく、システムリソースの削減にもつながることが分かります。
※4:Part 2のGraph 2の結果に対して、CPUリソースをより多く与えることでパフォーマンスが改善される可能性がある、という考察が記載されていました。
※5:Part 2のGraph 3の結果を受けての記載となります。
3. Pool Replica 2 vs. Pool Replica 3
Red Hat Storage Performance teamによる検証によると、Pool Replica数が2の時は、Pool Replica 3の時と比べ、Ceph OSDが書き込むデータ量が少なくなり、パフォーマンスが向上する、という結果が出ています。しかし一方で、(今回の検証環境である)All-Flash Cephクラスターにおいて、Pool Replica数が2と3を比べたとき、IOPSやレイテンシがどれほど変化するかを知る必要もあります(※6)。
※6:「Pool Replica数を減少させることでパフォーマンスが向上する」という報告はあるが、具体的にどの値がどの程度向上するのかがわからないために実施する、と解釈しています。
Pool Replica数の比較結果は以下のグラフの通りです。
Graph 4:Pool Replica 2 vs Pool Replica 3
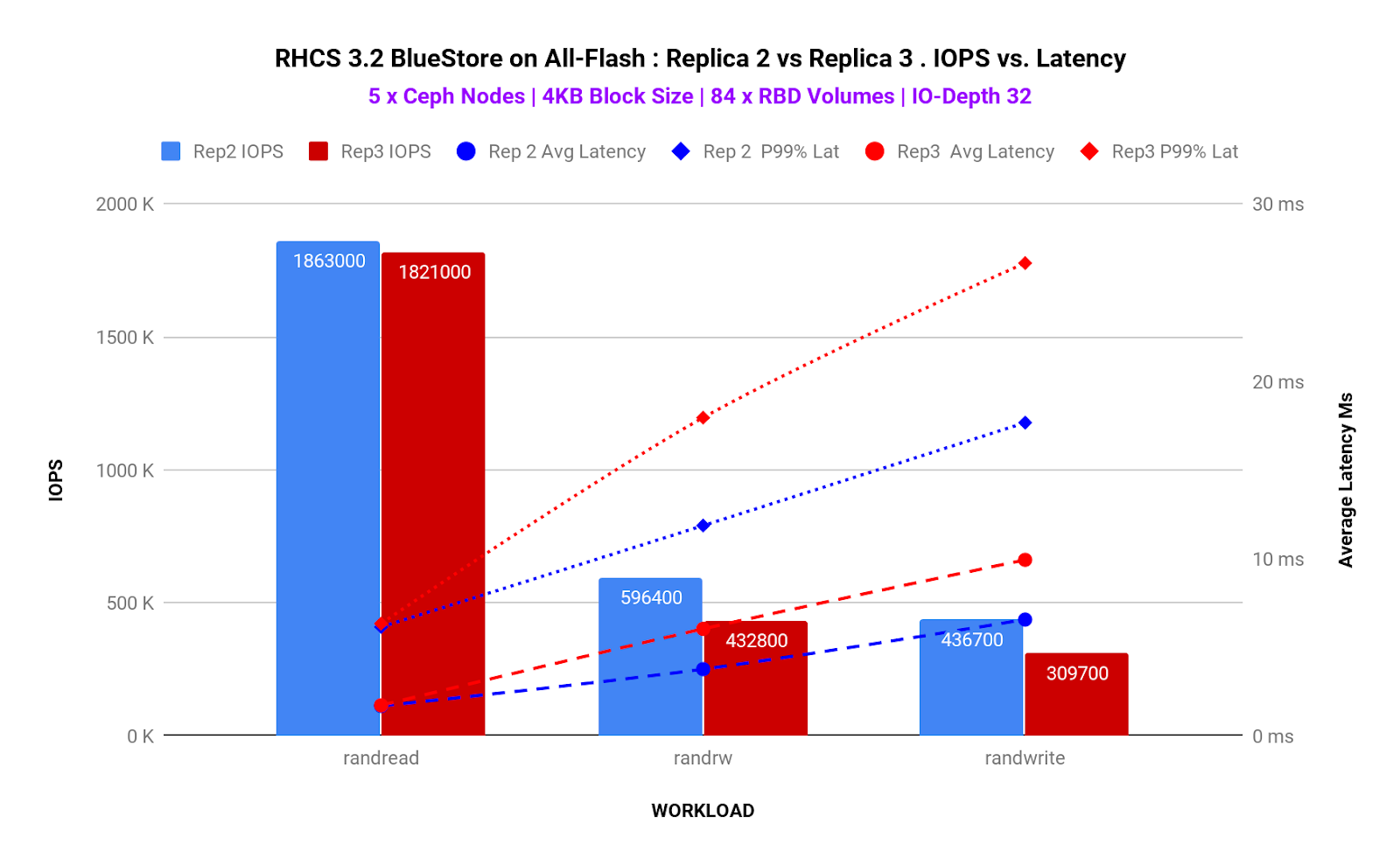
Table 2:Pool Replica 2・3のパフォーマンス改善率 (4K ブロックサイズ)
| Workload | IOPS | 平均レイテンシ | Tailレイテンシ (95%) | Tailレイテンシ (99%) |
|---|---|---|---|---|
| Random Read | -2.25% | +2.09% | +1.68% | +3.10% |
| Random Read-Write | -27.43% | +60.56% | +53.42% | +51.39% |
| Random Write | -29.08% | +51.45% | +52.49% | +50.96% |
上記グラフから以下のことがわかります。
- Pool Replica数を3から2に減らすことで、(Random Read-Write・Random Writeワークロードの)IOPSは約30%向上し、平均・Tailレイテンシは約50%減少しました(※7参照)。
- Pool Replica数を少なくすることでパフォーマンスが改善されることは分かったが、Pool Replicaサイズはそれを利用するメディアによって選択する必要があります。FlashメディアはHDDメディアに比べ、MTBF(Mean Time Between Failure)やMTTR(Mean Time To Recovery)は劇的に低くなります。一般にPool Replica数が2の時はFlashメディアを、Pool Replica数が3の時はHDDメディアを使用するのが安全と考えられていますが、それはストレージシステムの設計によって異なります。
※7:Japan Rook Meetupのこちらの発表でも、Replica数を少なくすることで、特にWriteパフォーマンスが向上する、という内容のものがありました。
4. BlueStore 8GB Cache vs BlueStore 4GB Cache
Ceph BlueStoreのRBDワークロードでは、BlueStore Cacheサイズがパフォーマンスに大きな影響を与えます。Onode Cachingは階層構造であり、Onodeがキャッシュされていない場合はDBディスクから読み取られてKV Cache(RocksDBのブロックキャッシュに利用するキャッシュ領域)へ格納し、最終的にはOnode Cacheへ格納されます(※8参照)。
データセット内のすべてのOnodeがBlueStoreブロックキャッシュに収まる場合、OnodeはDBディスクから読み取られることがなく、従ってKV Cacheへ格納されることもありません。これがRBDワークロードでは最適なシナリオとなります。しかし一方で最悪のシナリオとして考えられるのが、Onodeをディスクから読み取ることでKV Cache・BlueStore Cacheの両方に新しいOnodeデータを格納し、後から読み込まれる可能性のある古いOnodeを強制的に削除してしまう場合です(※9参照)。
※8:BlueStoreでは、すべてのメタデータはKV Database (RocksDB)へ格納されます。BlueStoreのメタデータは複数の種類があり、それらはNamespaceで分けられています。Onodeはオブジェクト毎のメタデータを指しており、Onode Cacheにキャッシュとして保存することで高速なパフォーマンスを実現します。Onodeがキャッシュされていない場合はRocksDBに格納されているデータを読み取ってきます。
※9:BlueStoreブロックキャッシュのサイズが大きければ、全てのOnodeがキャッシュに収まることもありますが、BlueStoreブロックキャッシュのサイズが小さい場合、新しいOnode Cacheが格納できず、DBディスクから読み取ることになります。それによって、もともとキャッシュされていた古いOnodeが強制的に削除されることになります。
※参考ドキュメント:
BlueStore Cacheサイズを変更した場合の検証結果は、以下のグラフのようになります。
Graph 5:BlueStore 8GB Cache vs BlueStore 4GB Cache
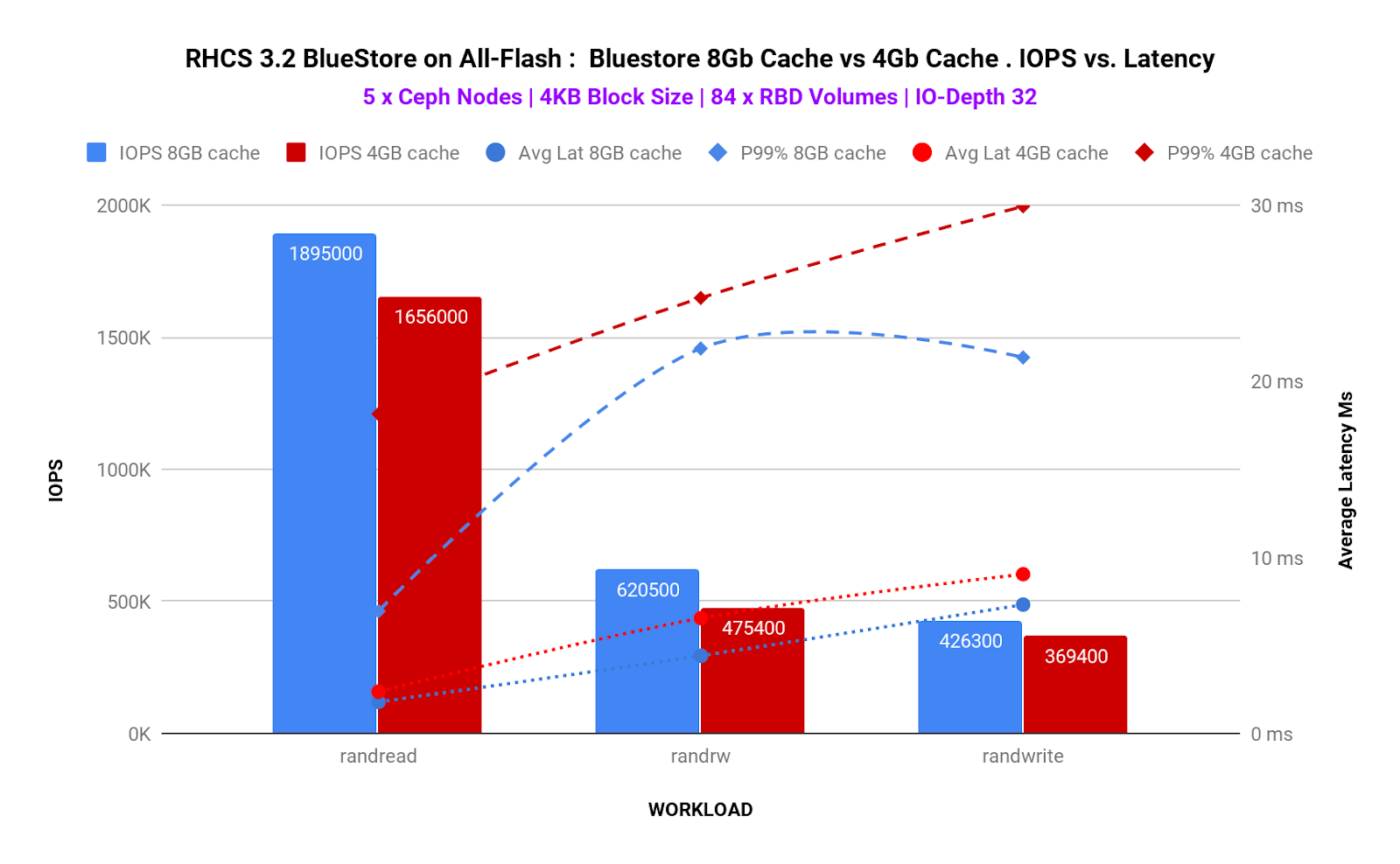
Table 3:BlueStore Cacheサイズによる改善率 (4Kb ブロックサイズ)
| Workload | IOPS | 平均レイテンシ | Tailレイテンシ (95%) | Tailレイテンシ (99%) |
|---|---|---|---|---|
| Random Read | +14.43% | -24.57% | -25.43% | -61.76% |
| Random Read-Write | +30.52% | -32.62% | -52.12% | -11.60% |
| Random Write | +15.40% | -19.10% | -24.31% | -28.68% |
上記グラフから、BlueStore Cacheサイズを増加することで、IOPS・レイテンシともに改善すること、特にRandom Read-Writeワークロードでは、IOPSが約30%向上、Tailレイテンシが約50%軽減されたことがわかります(※10参照)。
※10:グラフ中にはTailレイテンシ (95%)のプロットがないため、実際にはグラフから読み取ることはできないのですが、全てのワークロードにおいて、IOPS、平均・Tailレイテンシ (99%)は8GBのほうが低い値となっています。このため、少なくとも「Cacheサイズを増加することでパフォーマンスが改善される」ことは間違いなく言えそうです。
5. Optane vs No Optane as the WAL/RocksDB device
ここでは、Intel Optane P4800XをBlueStoreのメタデータデバイスとして利用すると、パフォーマンスが改善するかを検証しています。
Part 1にある検証環境では、Ceph Data用デバイスにIntel P4500、MetadataデバイスにP4800Xを採用していますが、ここでは、MetadataデバイスをP4500にした場合とP4800Xにした場合とで比較しています。
検証の結果は以下のグラフの通りです。
Graph 6:Optane vs No Optane

Table 4:Optaneによるパフォーマンス改善率 (4Kbブロックサイズ)
| Workload | IOPS | 平均レイテンシ | Tailレイテンシ (95%) | Tailレイテンシ (99%) |
|---|---|---|---|---|
| Random Read | +4.06% | -1.05% | -2.46% | -2.29% |
| Random Read-Write | +9.55% | -3.83% | -4.57% | -4.01% |
| Random Write | +7.23% | -4.40% | -13.08% | -13.82% |
上記グラフより、Optane P4800Xは全てのワークロードにおいてIOPS、平均・Tailレイテンシの改善が見られること、特にRandom WriteのTailレイテンシで大きな改善が見られることがわかります。
予測可能なパフォーマンスを達成することは本番環境のデータベースにおいては重要で、特にTailレイテンシに対してとてもセンシティブなものです。検証でP4800Xを利用した際、Tailレイテンシ(99%)のパフォーマンスは変動幅が小さいことが確認されました。このため、Optane P4800Xを利用することで、Tailレイテンシが改善されるだけでなく、本番環境のデータベースで重要となるTailレイテンシの予測可能で一貫性のあるパフォーマンスが期待できます。